Background
Machine learning (ML) powered methods are rapidly taking over the cybersecurity medium, performing a variety of complex tasks, including detection, prevention, and prioritization. Albeit not required by all methods, accurate labels of the training data at hand are generally necessitated to allow appropriate control over the underlying models’ characteristics and infusion of cybersecurity context. Nevertheless, the generation of credible labels in the cybersecurity domain embodies a great challenge that has yet to be properly addressed.
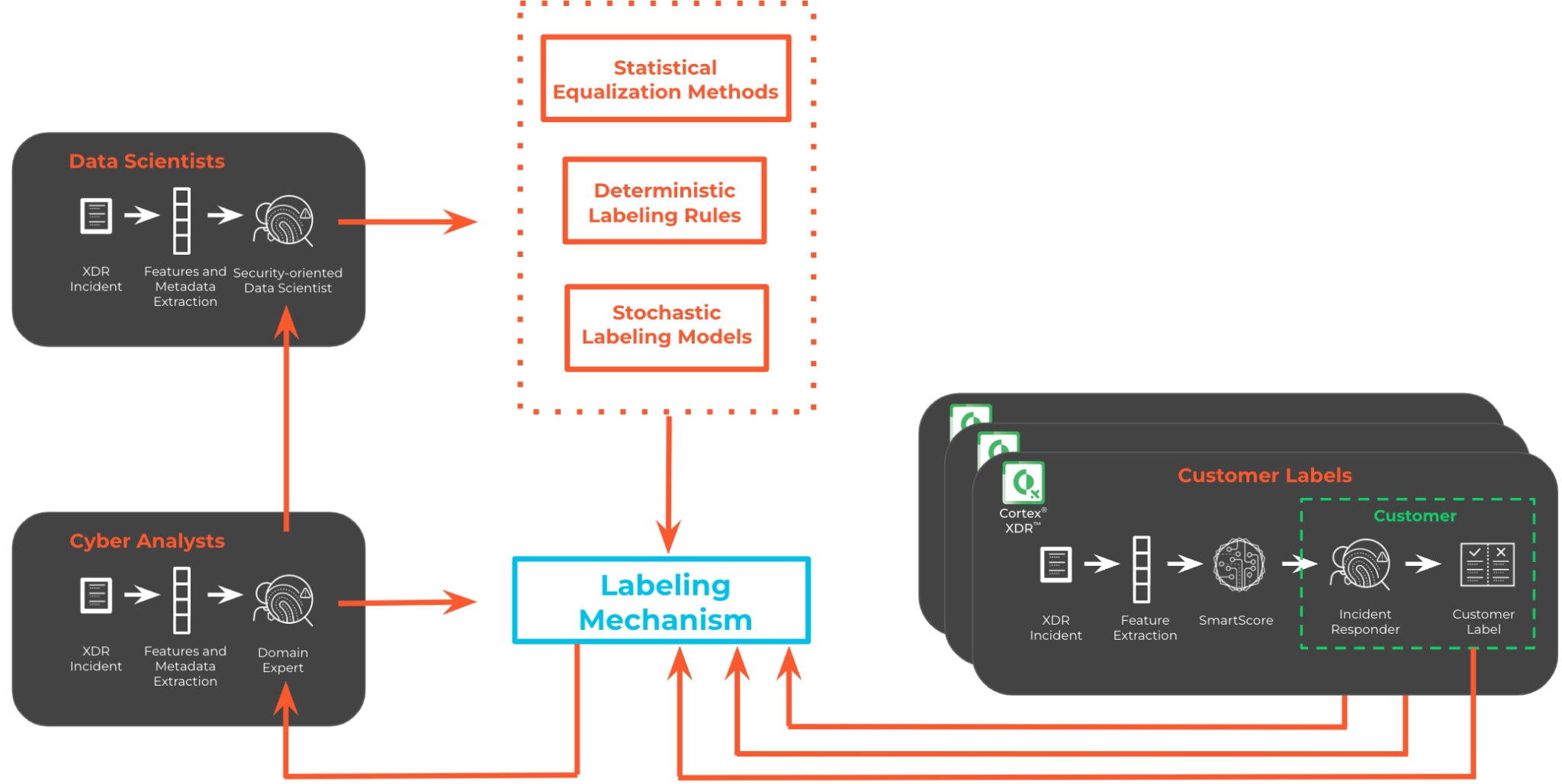
These labels help machine learning models learn and identify patterns associated with different types of cyber threats, enabling the models to classify and respond to potential security risks effectively. Generating credible labels involves using accurate and reliable information to annotate data, ensuring that the labeled data is representative of real-world cybersecurity scenarios. In the following, we will survey several labeling sources and techniques that can be leveraged and combined into contextual training labels. At Palo Alto Networks, we take advantage of those techniques to design our ML models and offer tailored solutions to our customers.
Customer Labels
The first and most straightforward source of labels is directly associated with the responses we receive from our customers, which are processed in an anonymized fashion. As the consumers of our products, we must account for their feedback in the tightest way possible when training our models, either directly via customer engagement or through product inherent resolutions. At first, it is best to merely consider larger customers and design partners. Focusing on a small and responsive set of design partners allows quick algorithmic modifications and rough performance validations. It also enables prompt detection and correction of tagging errors potentially made that may degrade the trained models. Then, to properly evaluate and tune the models further, labels from all customers should be considered. As the cybersecurity partner of choice for thousands of companies from different industries, globally, we are able to fuse and leverage a variety of responses and preferences.
Cyber Analysts Labels
While customer labels are indeed paramount, they are by no means sufficient to rely on for any vendor who wishes to lead the industry. That is, it is essential to directly incorporate domain experts to monitor, manually label, and improve the quality of the customer-based labels. Unfortunately, the capacity of domain experts is limited and can not be scaled to cover labels from thousands of customers, in particular over extended time frames. Therefore, to enable proper scaling, we employ various techniques that leverage the manually labeled data. For example, application of clustering techniques involving a subset of contextual features and metadata could extend the output of a manual labeling process by a great deal.
Deterministic Labeling Rules
ML models rely on features (either explicit or implicit) to describe the nature and settings of the task they are designed to perform. If explicit features are used, it is highly valuable to use some of them for the purpose of labeling, or label tuning, through predefined deterministic functions. For example, if a file is very rare when considering many customers from different industries, it is more likely to be suspicious.
Nevertheless, the implementation of deterministic labeling rules based on explicit features should be implemented with great caution to prevent the trained model from strictly adhering to the deterministic labeling rules. If the trained model strictly adheres to deterministic rules, it may overlook nuanced or complex patterns in the data that don't fit neatly into predefined categories
This rigidity could lead to false positives or false negatives, where the model incorrectly identifies or misses security threats, respectively. Therefore, implementing deterministic labeling rules with caution is essential to maintain the flexibility and adaptability of the model, ensuring it can accurately detect and respond to a wide range of cybersecurity threats. For instance, it's advisable to use clear-cut functions that are different from the math used in the trained model. Also, include irrelevant data when the model is working in real-world scenarios (like adding extra details from VirusTotal when dealing with files).
Stochastic Labeling Models
Unlike deterministic labeling methods, which rely on predefined rules to assign labels to data, stochastic labeling involves probabilistic decision-making. In stochastic labeling models, labels are assigned based on statistical probabilities, taking into account various factors and uncertainties in the data.
In certain cases, we have access to unique data fields, such as verdicts or enhancements from independent internal research tools and dynamic statistics of involved entities. These verdicts are tailored to address specific aspects of the data, allowing for more nuanced and detailed labeling based on the unique characteristics of each aspect. This approach helps in providing more granular insights and decision-making capabilities, especially in complex datasets where different aspects may require different interpretations or actions.
While they only describe a portion of the model’s input, focusing on some of them through designated models yields a set of aspect-specific verdicts—labeling decisions or outcomes that are specific to particular aspects of the data being analyzed—or labels that can be combined into a unified credible label. They may also involve any sort of textual input or threat intelligence that are not directly available to the model through its features. Overall, while stochastic labeling models offer a way to generate aspect-specific verdicts for cybersecurity tasks, they can also pose risks related to data interpretation, model robustness, security vulnerabilities, and evaluation complexities.
Statistical Equalization Methods
The previously discussed techniques individually target a single model input looking to assign to it a single credible label. In contrast, it may be beneficial to consider some, or even all, data samples at once. This can be performed in several ways. For example, one may investigate the labels’ distribution obtained from one or several individual labeling techniques. Then, considering a “True” reference labels’ distribution is within our reach of hand, we can adapt or tune the distribution in a way that matches the reference distribution better. Note that this approach requires close monitoring and may be performed either in a purely statistical manner or by incorporating label-tuning boundaries based on contextual features (for example, an individual label modification can not exceed some feature-related threshold).

In summary, assigning credible and meaningful labels to cybersecurity data embodies a great challenge, in particular when required to be performed at scale. We have proposed a number of techniques that can be used and adapted considering the nature of the scenario at hand and the task to be performed. Nevertheless, it is mandatory to keep in mind that any labeling process should be accompanied by tight monitoring and involve different means to ensure that the quality of the assigned labels is high. To be on the safe side, this should consist of both manual investigation by our experts as well as automatic monitoring tools. At Palo Alto Networks, we manipulate and investigate the data and assigned labels from a variety of perspectives to guarantee that the output of the labeling process is indeed credible and describes the data in the best possible way.
To dive deeper into this subject, please read our other relevant blogs: Battling macOS Malware with Cortex AI, and Beating Alert Fatigue with Cortex XDR SmartScore Technology