
This blog post is the first in a series that exposes security risks, possible attack vectors, and how to hunt and prevent them using data detection and response (DDR).
When correctly configured, Redshift’s security features and capabilities protect sensitive data from leaks or other security incidents. However, often, organizations struggle to correctly configure and implement these features because the manual processes can be time-consuming and require specialized skills.
To mitigate security and privacy risks, you need to appropriately configure security features and follow practices. Implementing rigorous access controls is the first step to protecting sensitive data stored in Redshift.
Why Research Data Security in Redshift?
Redshift is a fully managed data warehouse service (such as Google BigQuery and Snowflake). Based on PostgreSQL, its performance enables extremely fast query execution on extremely big datasets by employing several features such as:
- Massive Parallel Processing (MPP)
- Columnar data storage
- Data compression
According to Amazon, Redshift delivers business value with 2-7 times better price performance on high-concurrency and low-latency real-world analytics. A popular service, Redshift is used by more than 20,000 companies.
As a widely used data warehouse containing sensitive personal and intellectual property data, you need to secure your deployment to comply with privacy laws and mitigate data breach risk.
Implement Least-Privileged Access to Sensitive Data on Redshift
Access control is the front gate to the data and the assets containing the data.
Features like RBAC and SSO are the first security guards to limit access to sensitive information inside the organization.
During our work with customers we have seen so many cases of excessive privileges that are difficult to track and exposing their data to a real danger. Strong access control policy can help to protect against external and internal threats by limiting users access to sensitive data.
Using SSO Authentication
Redshift offers identity federation as well as database user management.
With the Redshift browser SAML plugin, you can launch a custom AWS SSO SAML application that provides the SAML attributes needed to connect to Amazon Redshift using a JDBC/ODBC client.
When configured, AWS SSO authenticates the user identity against the identity source directory.
Bypass Redshift User Authentication with IAM Access
In most cases, Redshift users log in with their database username and password. However, to prevent Redshift administrators from maintaining usernames and passwords, AWS enables you to create user credentials based on IAM credentials to access the databases in Redshift.
The AWS Redshift API GetClusterCredentials returns the username and a temporary password for the database along with temporary authorization to log in.
To get the credentials, you need to assign a policy with the redshift:GetClusterCredentials to your User/Role.
After the temporary credentials are obtained, Redshift-data API can perform SQL queries.
Usually, you need to specify a user in the request parameters. However, if the "AutoCreate" option is "True", a new user is created automatically.
Pro Tip
It’s recommended to know exactly which users and roles have “redshift:GetClusterCredentials” and “redshift-data” permissions, as they can potentially connect and read/write your sensitive data.
To check if there are policies allowing to generate temporary credentials for Redshift cluster, you can follow these steps and search for policies that allow the action “redshift:GetClusterCredentials”:

After identifying the relevant policies, check the attached users, groups and roles. Further, you should also review inline policies for users and roles that may contain this privilege.
To get temporary credentials to connect to Redshift with cli:
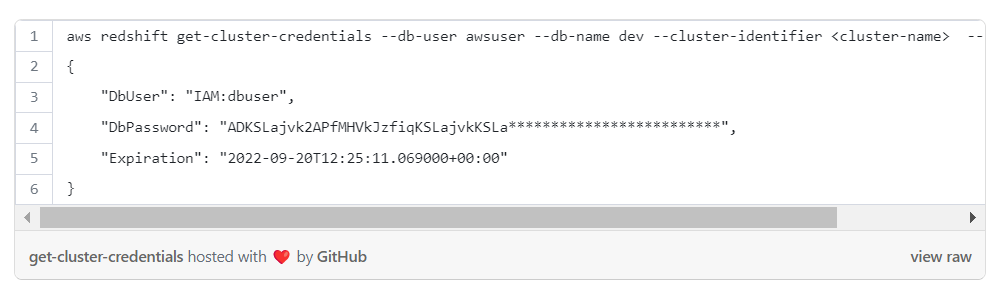
After the credentials are obtained, it’s possible to execute queries against Redshift by running the following cli command:

Protecting Data in Redshift with RBAC Authorization
Access to database objects, such as tables and views, is controlled by local users, roles and groups in the Amazon Redshift database. These users are managed separately from AWS standard IAM with local users and roles acting similarly to standard RDBMS mechanisms.
The local users and roles act the same as the standard RDBMS mechanism. Redshift admin can create users and groups and assign them the relevant privileges they need. It’s recommended to create a user per identity so in the event of a security incident it’ll be possible to track and monitor what data was accessed or even prevent unauthorized access before it happens.
The default users are the "rdsdb" user, and the user you created in the creation process.
They’re both Supeusers, when the user rdsdb is used internally by Redshift to perform routine administrative and maintenance tasks and only rdsdb can update the system catalog.

Fine-Grained Data Security with Access Control
Redshift gives you fine-grained data access controls that allow you to mitigate risk at the column- and row-levels.
Column-Level Security
You can grant user permissions to a subset of columns. Similar to managing any database object, column-level access control can be done by using GRANT and REVOKE statements at the column level.
Row-Level Security (Rls)
To ensure that sensitive data is only accessible by those who need it, Redshift provides fine-grained access control at the row level with its row-level security (RLS) feature.
Based on the foundation of role-based access control (RBAC), the RLS feature restricts who can access specific records within tables based on security policies defined at the database object level. Unlike other tools that require you to create different views or use different databases and schemas for different users, this approach is sustainable.
An RLS policy can control whether Amazon Redshift returns any existing rows from a table in a query by specifying expressions.
Protecting Sensitive Data on Redshift by Limiting Network Access
Disable Public Access
Redshift isn’t publicly accessible by default so access to redshift clusters is possible only from inside the VPC or through a VPN. If the Public Access configuration is enabled, it’s possible to connect to the Redshift cluster from anywhere without any restrictions.
Pro Tip
We strongly recommend blocking public access to Redshift clusters.
Disable public access with cli:

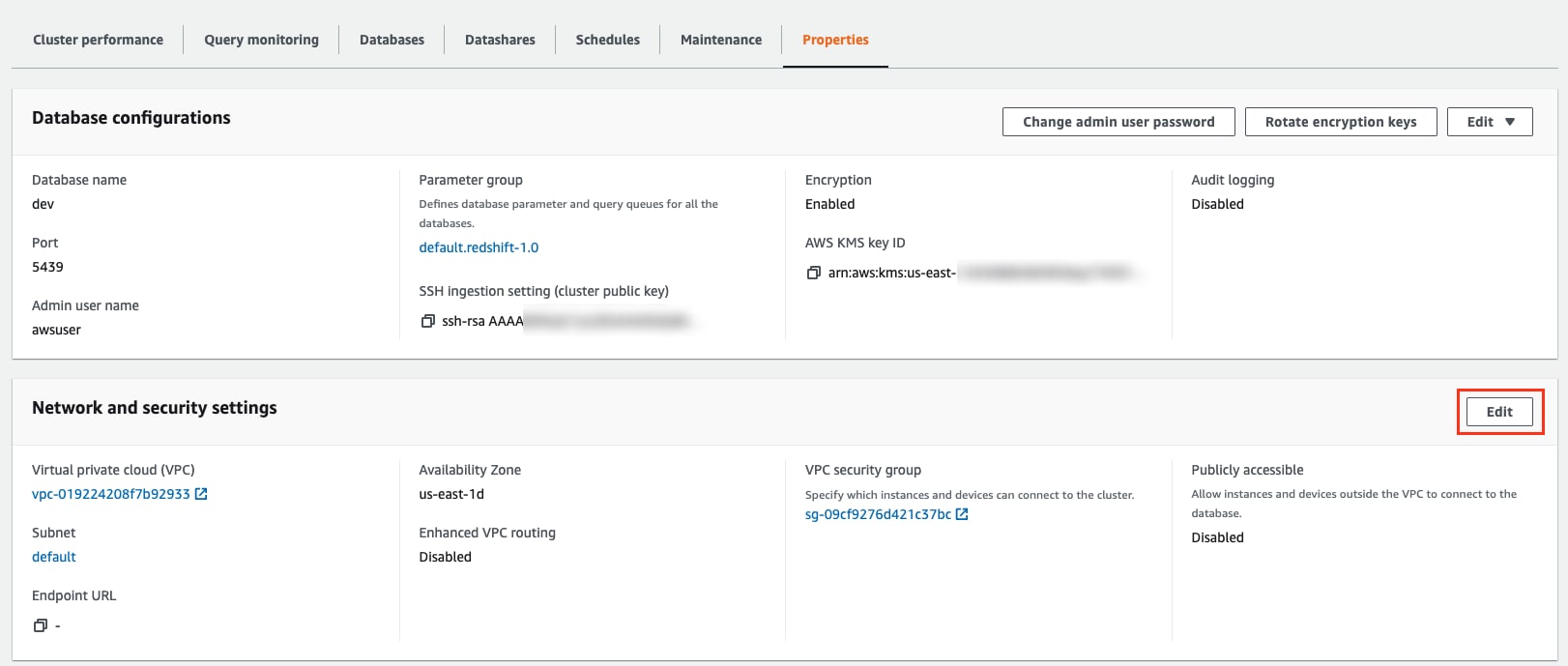
Disable public access with AWS console:
Under the “Properties” tab, click “Edit” on the “Network and security settings” section:
Control Network Access with Security Group
Another option to control access to the Redshift cluster is by setting the cluster’s security group inbound rules. The security group is like firewall rules for the specific AWS service, by limiting to specific IPs, subnets, ports etc we can add another layer of security to our Redshift cluster.
Pro Tip
It’s recommended to use the security group as a second layer of security and not use it together with public access to avoid mistakes that can easily lead to your data being exposed publicly.
Enable Enhanced VPC Routing
When enhanced VPC routing is disabled, Amazon Redshift routes traffic through the internet, even traffic to other services within the AWS network.
Pro Tip
It’s recommended to enable enhanced VPC routing to add another layer of security to your data at-transit.
To enable enhanced VPC routing with cli:

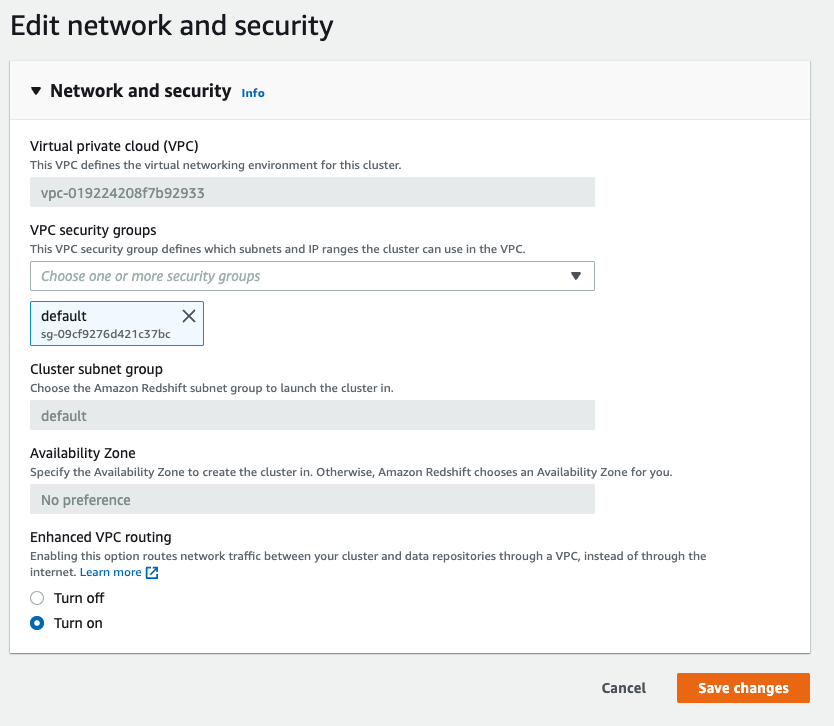
To enable enhanced VPC routing with the AWS console:
Under the “Properties” tab, on the “Network and security settings”, click on “Edit”.
Change the configuration to “Turn on” then click “Save changes”:
Manage Your External Data Sources
As part of the AWS ecosystem, Redshift can use other services as data sources, to import or export data.
IAM Role Association with Your Cluster
Redshift can be associated with IAM roles that authorize the cluster to access external data sources like S3, DynamoDB etc.
Pro Tip
It’s recommended to make sure that the roles are configured correctly with the least privilege principle to avoid data leakage.
We will dig deeper into the data sources risks in our next blog post.
Add or remove roles with cli:
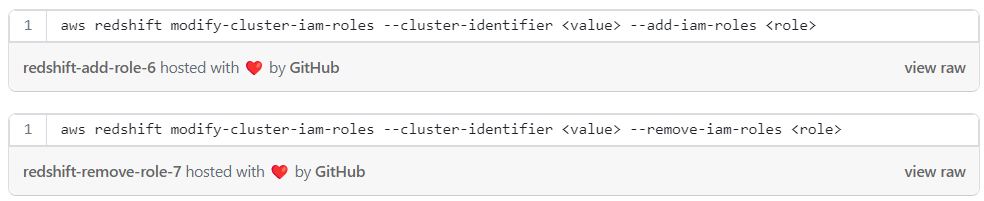
Add or remove roles with the AWS console:
Under the “Properties” tab, on the “Cluster permissions” section, click on “Manage IAM roles”
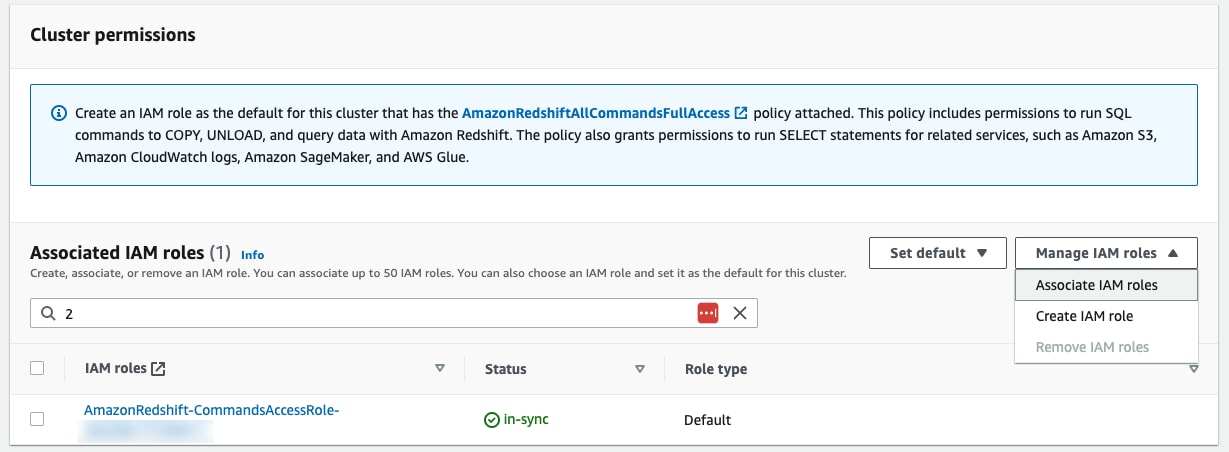
Data Sharing with Redshift Clusters
With the Redshift datashares feature it’s possible to share data across Redshift clusters in the same account or in different accounts. The feature gives instant access to data without the need to copy or move it. It's important to make sure that the cluster shares only data that is intended to be shared.
It’s possible to share data on schema db level, schema level or table level.
Keep in mind that any data that leaves the cluster reduces the control on it, don’t share sensitive data that shouldn’t leave the cluster.
Pro Tip
To get full visibility to your current data shares status in your account, please follow the next steps.
To show Redshift data shares from cli:

To see your data shares from inside Redshift:

Pro Tip
Reduce the scope of sensitive information shared with other accounts.
To modify the tables or schemas that shared in the datashare you can use the alter command:

Another important aspect when creating a data share is whether your data share can be shared with Redshift clusters that are publicly accessible.
Pro Tip
It’s recommended to limit the data share so it won’t be shared with public clusters.
Below are some examples for creating data shares:

In case that the data share is already set as publicly accessible it’s possible to modify this setting to false:

How Prisma Cloud Can Help with Data Security Posture Management for Redshift
Redshift is an awesome service with great capabilities that offers many security features. We reviewed many security aspects that need to be considered, reducing the attack surface is the most challenging but important part of prevention.
Appropriately configuring Redshift access controls may be challenging, but it can be done manually. Continuously monitoring your controls to ensure they function as intended, though, becomes a challenge, especially as you scale your data analytics usage.
Prisma Cloud prevents exposure of sensitive data with full data security posture management (DSPM) capabilities, highlighting data misconfigurations, access anomalies and data vulnerabilities that increase the risk of a data breach. Dig enriches DSPM with near real-time data detection and response (DDR) to ensure an immediate handling of newly discovered data-related incidents by integrating with your existing security solutions.
What's Next?
In our next post in the series of Redshift inside-out, we’ll continue to review security features of Redshift, including encryption, backups and logs. More to come in our series exploring potential Redshift attack vectors and how to hunt and prevent them.