AI tends to be understood as one coherent field of study and application where similar solutions apply for all the use cases. The reality is that applying AI in real-world environments with high precision requires specialization in the specific field of study, and each use case has unique challenges. Applied AI in cybersecurity has many unique challenges, and we will take a look into a few of them that we are considering the most important.
One — Lack of Labeled Data
Unlike many other fields, data and labels are scarce in the cybersecurity space and usually require highly skilled labor to generate. Looking at a random set of logs in most cybersecurity logging systems will most likely result in zero labels. Nobody labeled a user downloading a document as malicious or benign; nobody provided data if a login was legitimate or not. This is unique to cybersecurity. In many other fields of applied AI, labels are abundant and allow for using techniques leveraging those labels.
Because of the lack of labels, most detection approaches use unsupervised learning, such as clustering or anomaly detection, as it doesn’t require any labels. But, that has considerable downsides.
Two — Anomalous Is Not Malicious
Following up on the last point, many approaches use anomaly detection and clustering to detect suspicious activities. While these techniques have some merit, they have the unfortunate secondary effect of detecting many benign activities.
Reviewing any mature network environment will present many assets and activities that are anomalous by design, like vulnerability scanners, domain controllers, service accounts and many more. These assets create considerable noise for anomaly detection systems, as well as alert fatigue for a SOC analyst reviewing the alerts generated by such systems. Whereas attackers, most of the time, will remain below the threshold and can remain undetected by such systems as the level of anomalous activity to achieve their goals is often considerably lower than what is done by the aforementioned assets.

On the other hand, supervised learning systems can remediate this issue and filter out anomalous by design activities and assets, even when using unsupervised techniques as part of the model. But, they require labels, and we’ve established that those are hard to find.
Three — Domain Adaptation and Concept Drift Are Abundant
Domain adaptation and concept drift are key issues in data science. Models are usually trained on a subset of data many times in a simulation of the real world. When that model is losing touch with the real-world data, leading to poor precision and recall, you would call this “Concept Drift.” Alternatively, if the model doesn’t provide the same result across multiple situations, you would call that “Domain Adaptation.”
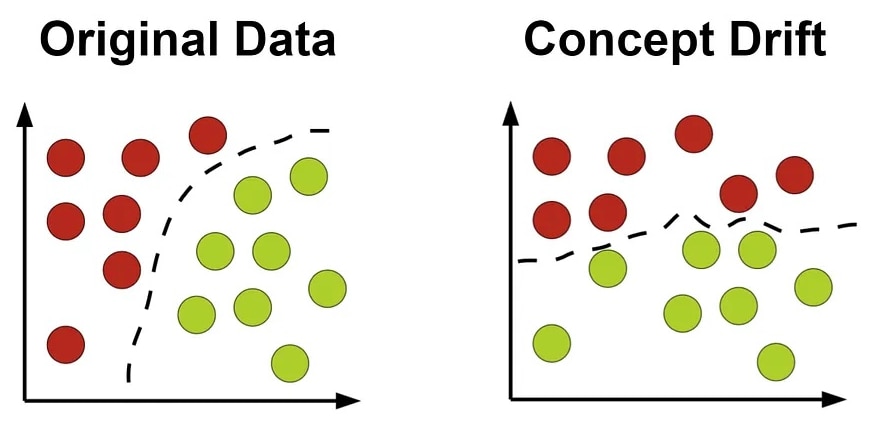
In the cybersecurity space, the world is always changing as both attackers and defenders try to stay ahead of one another, leading to considerable concept drift. By reviewing the MITRE definition of process injection we can see that the meaning of the term has changed considerably in the last couple of years with new subtechniques being added all the time. That will probably change again as attackers evolve. Models trained to detect such activity require retraining, or they become obsolete.
Additionally, models trained in one environment don’t necessarily generalize well for others. Due to the large set of configurations in real-world environments, models trained for cybersecurity issues tend to have considerable domain adaptation issues. Imagine a model trained on a lab environment, that model has never been fed with examples of the myriad of configurations applicable to a specific application, let alone how different applications might change the behavior due to other installed applications.
Four — Domain Expertise Is Critical and Hard to Find
Unlike many other domains, validating models requires unique cybersecurity expertise. Classifying if a traffic light is green or red doesn’t need a specialist, whereas classifying if a file is malicious requires a malware analysis expert. Building AI models for cybersecurity requires trained experts that can validate the results and label cases to assess key performance indicators (KPIs). As there’s a scarcity of those experts and doing supervised learning is the golden path for cybersecurity AI, that creates another key challenge to doing AI correctly in this space.
Five — Explainability Is Key for Successful Incident Response
Even if you can train the best model that has high precision and recall but the output isn’t clear, it’s not a good model. Incident response requires a clear understanding of what actually happened to properly respond to the threat at hand. Models are just tools that help reach the goal of detecting the attack, but without explaining what happened, those don’t translate into actual security value for analysts. This creates challenges for unsupervised learning as it’s harder to explain the model behavior. It also creates a high bar for any supervised model that must provide a proper explanation on what happened, why it’s important, and how it’s detecting the activity.
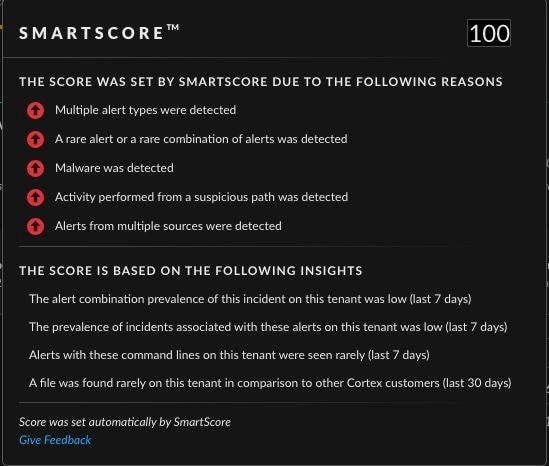
Cortex — Cybersecurity AI Applied in Scale
Cortex has applied solutions for unlabeled data that is leveraging a patented, semi-supervised learning technique and multiple other techniques to leverage the scale of data that the Cortex platform collects. Our entire stack of prevention, detection and prioritization systems, including Local Analysis, Cortex Analytics and SmartScore, are leveraging supervised learning that aims to detect malicious data and ignore the anomalous by designing data that is benign. Furthermore, we have invested considerably into explainability and transparency with documentation and explainability models where needed.
Key Takeaways
Specialization Is Pivotal: Understand that applying AI in cybersecurity requires specialization in the specific field and use case. Each use case has unique challenges, and a one-size-fits-all approach doesn't work. Tailor your AI solutions to the specific cybersecurity challenges you face.
Lack of Labeled Data: Unlike many other fields, cybersecurity often lacks labeled data, making supervised learning challenging. Embrace unsupervised learning techniques, like clustering and anomaly detection, but be aware that they can generate false positives, contributing to alert fatigue.
Domain Adaptation and Concept Drift: Recognize that the cybersecurity landscape is evolving, leading to concept drift and domain adaptation issues. Models trained on outdated or limited data may become obsolete. Regularly retrain models and consider the dynamic nature of the threat landscape.
Domain Expertise Is Essential: Building AI models for cybersecurity requires domain expertise. Validate models with cybersecurity experts who can assess key performance indicators. Scarcity of such experts can be a challenge, but their input is crucial for effective AI implementation.
Explainability Matters: In incident response, explainability is crucial. Models must not only detect threats but also provide clear explanations of what happened, why it's important, and how they detected the activity. Invest in AI solutions that prioritize explainability for successful incident response.
Like What You Read? Stay Up-to-Date by Subscribing to our SecOps Blogs
Learn More About AI’s Impact on Cybersecurity
Register for Symphony 2024, April 17-18, to explore the latest advancements in AI-driven security, where machine learning algorithms predict, detect and respond to threats faster and more effectively than ever.